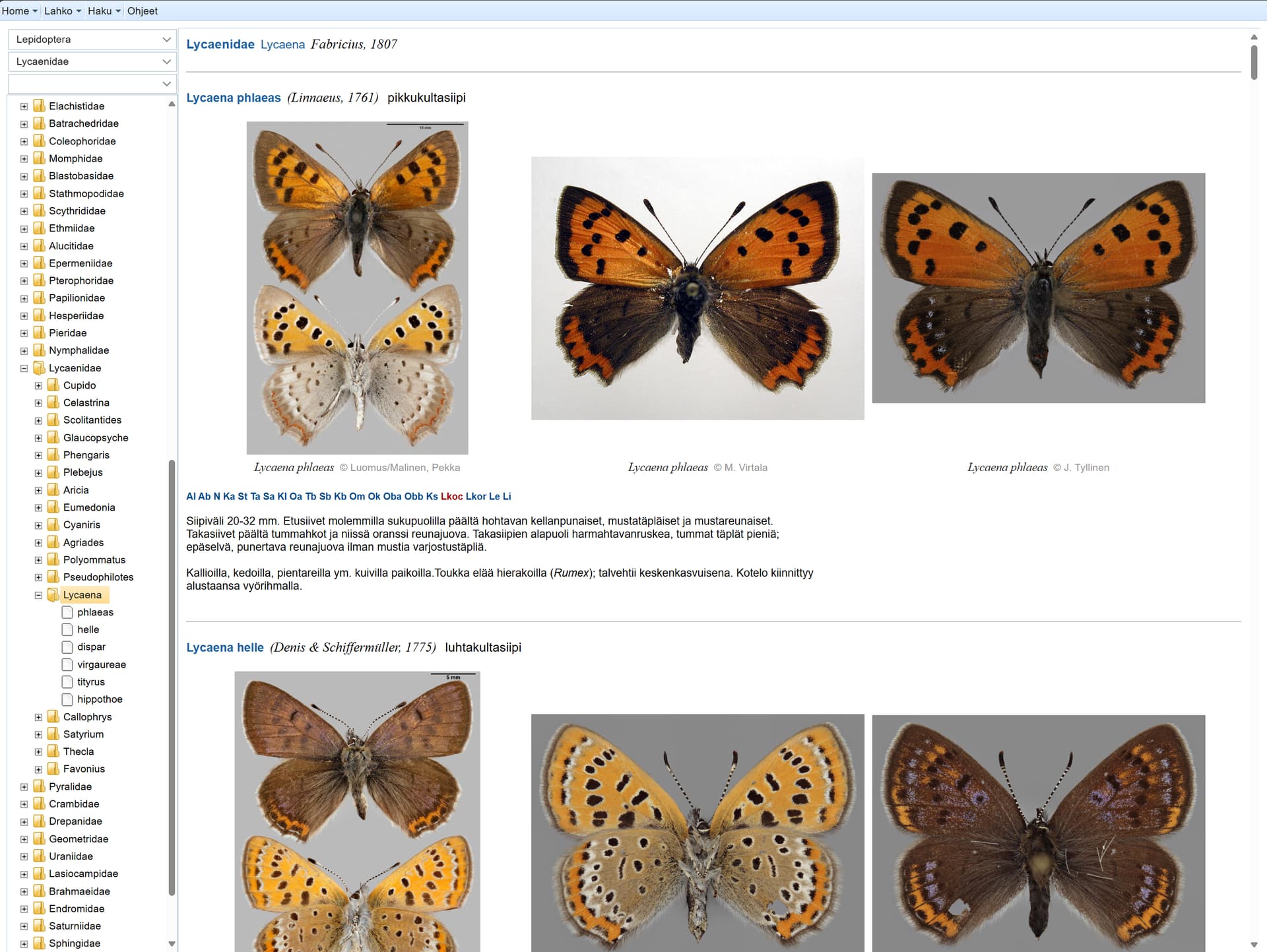
En tunne lainkaan Google Lensin toimintaa enkä tiedä mihin kuvien käyttöoikeus perustuu. Ainakaan lajitietokeskus ei ole voinut myydä Google Lensille käyttöoikeuksia kuviimme koska kuvien lisenssioikeudet ovat kuvaajilla. Ehkä joku muu täällä tai lajitietokeskus tietää mistä on kyse. Voi olla ihan laillistakin käyttöä, itse en siis asiaa tunne.
Valokuvauspiireissä näistä AI -mallien kuvavarkauksista on puhuttu paljon ja oikeusjuttuja on meneillään runsaasti. Esimerkiksi Getty Images, joka on suurimpia kuvatoimistoja, on haastanut isot AI -talot oikeuteen eräänlaisella joukkokanteella kuvaajiensa puolesta. Tämä ei siis ole mikään uusi juttu ja on siis puhuttanut kuvaajapiirejä paljon ja pitkään.
Yksi kaveri keksi kysyä AI chatbotilta analyysiä siitä mitä seuraamuksia tuosta oikeudenkäynnistä voisi olla. Vastaus on ihan hauska taikka kiinnostava ja selittää aika hyvin mistä on kyse. Kopsaan vastauksen tähän vaikka ei nyt suoraan liity lajitietokseskuksen palveluihin millään lailla. On kuitenkin mielestäni yleisesti kiinnostava kuvien tekijänoikeuksien kannalta ja selittää ainakin osaltaan suurta latauspainetta kuviimme.
I asked an AI chatbot: ‘If Getty Images or the US lawsuit wins the case, what will be the repercussions for the industry?’"
and I got this answer:
"You’re asking about the potential “nuclear option” for the AI industry. If Getty Images or the US lawsuit wins a landmark case establishing that training AI models on copyrighted data without a license is infringement, the repercussions would be seismic and reshape the entire generative AI landscape.
Here’s a breakdown of the likely impacts:
-
Financial Devastation for Many AI Companies:
Massive Damages: A ruling against AI companies would expose them to colossal damages. The scale of training data (millions to billions of images/texts) means even a small per-item royalty or infringement penalty could amount to billions of dollars, potentially bankrupting many current AI startups and even significantly impacting larger tech giants.
Licensing Costs Skyrocket: Even if companies aren’t shut down, they would be forced to retroactively and prospectively license the data. This would lead to huge ongoing costs, driving up the price of AI services and potentially making them unaffordable for smaller businesses or individual creators.
Reduced Investment: Investors would become extremely wary of funding generative AI companies that rely on scraped data, fearing ongoing legal battles and massive liabilities.
-
Fundamental Shift in AI Model Development:
“Clean” Datasets Become Paramount: AI companies would pivot immediately to models trained exclusively on:
Public Domain Content: Works where copyright has expired.
Properly Licensed Data: Companies would need to strike explicit licensing deals with content creators, stock agencies (like Getty itself), and publishers. This would create a new, lucrative market for content providers but would be a significant hurdle for AI developers.
Synthetic Data: AI models could potentially train on data that is itself AI-generated or synthetically created, but this has its own challenges regarding quality and diversity.
Retraining and Obsolescence: Many existing, powerful AI models that were trained on vast, uncurated internet datasets might become legally "tainted" and effectively obsolete overnight. Companies would need to retrain new models on compliant data, a time-consuming and expensive process.
-
Impact on AI Services and Products:
Higher Costs for Users: If AI companies have to pay significant licensing fees, those costs will inevitably be passed on to end-users through subscriptions, API fees, or other charges.
Reduced Accessibility: The barrier to entry for using powerful AI models might increase, making them less accessible to hobbyists, small businesses, and non-profits.
Limited Capabilities (Initially): Until new “clean” models are trained and optimized, the diversity and quality of AI-generated content might temporarily decrease as models adapt to more constrained (but legally compliant) datasets.
Emphasis on Human-in-the-Loop: There would be an even greater emphasis on AI as a tool for human creativity, where significant human input ensures copyrightability of the final output, rather than purely prompt-generated content.
-
Empowering Content Creators and Copyright Holders:
Stronger Bargaining Position: Artists, writers, photographers, musicians, and other creators would gain significant leverage in negotiations with AI companies. They could demand fair compensation and control over how their work is used for training.
New Revenue Streams: Licensing data to AI companies could become a major new revenue stream for creative industries.
Renewed Focus on Human Creativity: The legal victory would reinforce the value and protected status of human-authored content, potentially alleviating fears that AI will completely devalue creative professions.
-
Regulatory and Legislative Scrutiny:
Global Ripple Effect: A major US ruling would likely influence legal interpretations and potential legislation in other countries, pushing for similar protections for copyright holders worldwide.
Calls for New Laws: While some argue existing copyright law is sufficient, others might push for specific AI-focused legislation to clarify rules around training data, authorship, and liability.
-
The “Fair Use” Debate Crystallized:
The lawsuits are largely about the interpretation of “fair use” in the context of AI training. A win for Getty would mean that courts view such mass, commercial scraping for training as not fair use, directly contradicting the arguments made by many AI developers.
Exceptions and Nuances:
Adobe Firefly's Relative Safety: As discussed, Adobe Firefly, trained on licensed data, would be in a much stronger position. This might give Adobe a significant competitive advantage in the market.
Focus on the "Black Box": The lawsuits primarily target the training data that goes into the AI model (the "input"), not necessarily every single image that comes out (the "output"). However, if the input is deemed infringing, then the resulting model (and potentially its outputs) could also be seen as tainted.
Settlements: Many of these cases could still result in large settlements rather than definitive court rulings, which might involve confidential agreements and licensing deals, still leading to many of the same financial and operational shifts without setting a broad, binding legal precedent through a court decision.
In essence, a win for Getty Images or the US lawsuit in the manner described would signal that AI companies cannot simply ingest the world’s copyrighted content for free. It would force a more ethical, licensed, and potentially more expensive, but ultimately more sustainable, path for the development and commercialization of generative AI."
I truly hope that happens.